End-to-end full-duplex speech models feed user audio through an always-on LLM backbone, yet the speaker privacy implications of their hidden representations remain unexamined. Following the VoicePrivacy 2024 evaluation protocol with a lazy-informed attacker, we show that the hidden states of SALM-Duplex and Moshi leak substantial speaker identity across all transformer layers. Layer-wise and turn-wise analyses reveal that leakage persists across all layers, with SALM-Duplex showing stronger leakage in early layers while Moshi leaks uniformly, and that Linkability rises sharply within the first few turns. We propose two streaming anonymization setups using Stream-Voice-Anon: a waveform-level front-end (Anon-W2W) and a feature-domain replacement approach (Anon-W2F). Anon-W2F raises EER by over 3.5x relative to the unprotected baseline, approaching the 50% random-chance ceiling, while Anon-W2W retains over 90% of the baseline sBERT score with sub-second response latency (FRL under 0.8 s).
Index Terms: speaker anonymization, full-duplex speech, privacy, speaker verification, speech agents
Proposed Anonymization Setups
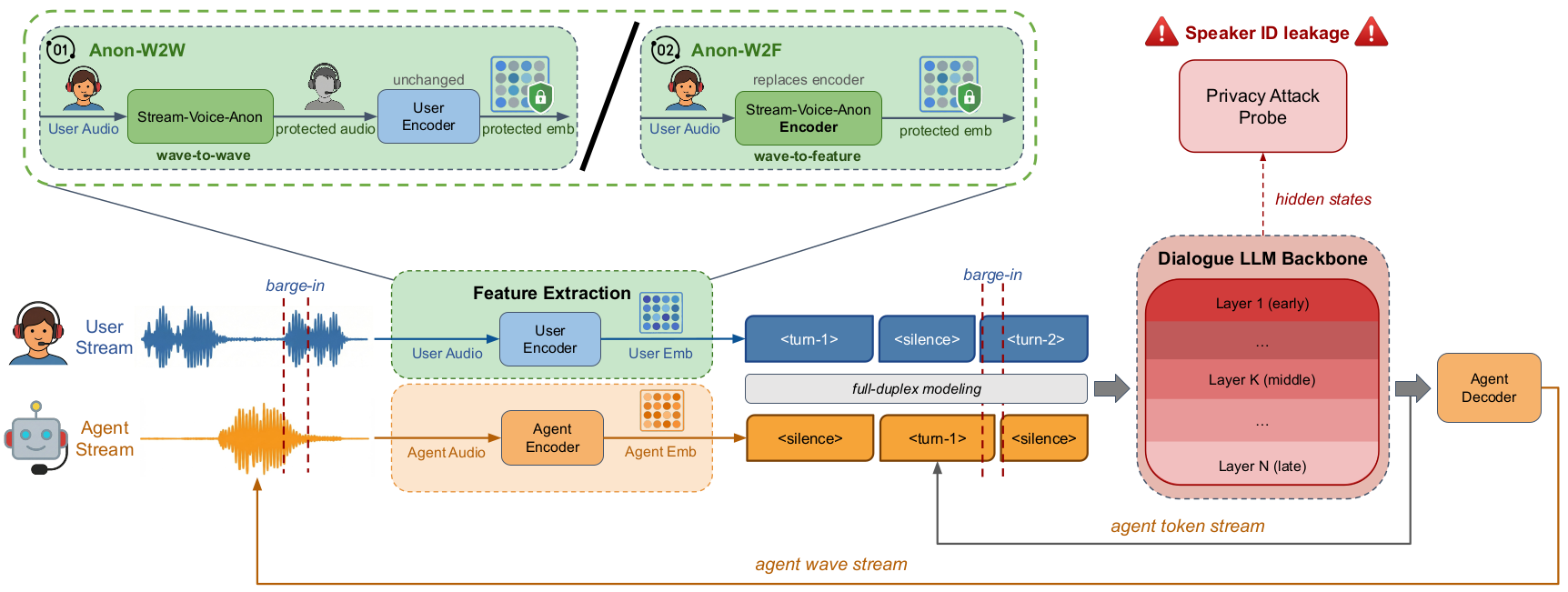
Figure 2: Overview of the original SALM-Duplex pipeline and proposed anonymization setups. The main diagram shows the ASR-based encoder baseline: an ECAPA-TDNN probe attached to the LLM's hidden states (red dashed path) reveals substantial speaker identity leakage. The Anon-W2W inset (upper left) prepends Stream-Voice-Anon to anonymize the waveform before the unchanged ASR encoder. The Anon-W2F inset (upper right) replaces the ASR encoder with the Stream-Voice-Anon encoder (anonymization active) and fine-tunes the LLM, eliminating the redundant waveform synthesis step.
Anon-W2W (wave-to-wave)
Stream-Voice-Anon transforms the raw user waveform into an anonymized waveform before it is fed to the dialogue model. The original encoder is retained. Evaluated on both SALM-Duplex and Moshi.
Anon-W2F (wave-to-feature)
The continuous encoder is replaced with a discrete encoder and Stream-Voice-Anon's anonymization module operates natively on discrete tokens, eliminating the redundant waveform synthesis step. Evaluated on SALM-Duplex.
Privacy Probe (attacker)
An ECAPA-TDNN speaker verification model trained from scratch on hidden state representations. Equal Error Rate (EER) is the primary metric; EER = 50% = random chance (perfect anonymization).
Turn-Length Privacy Analysis
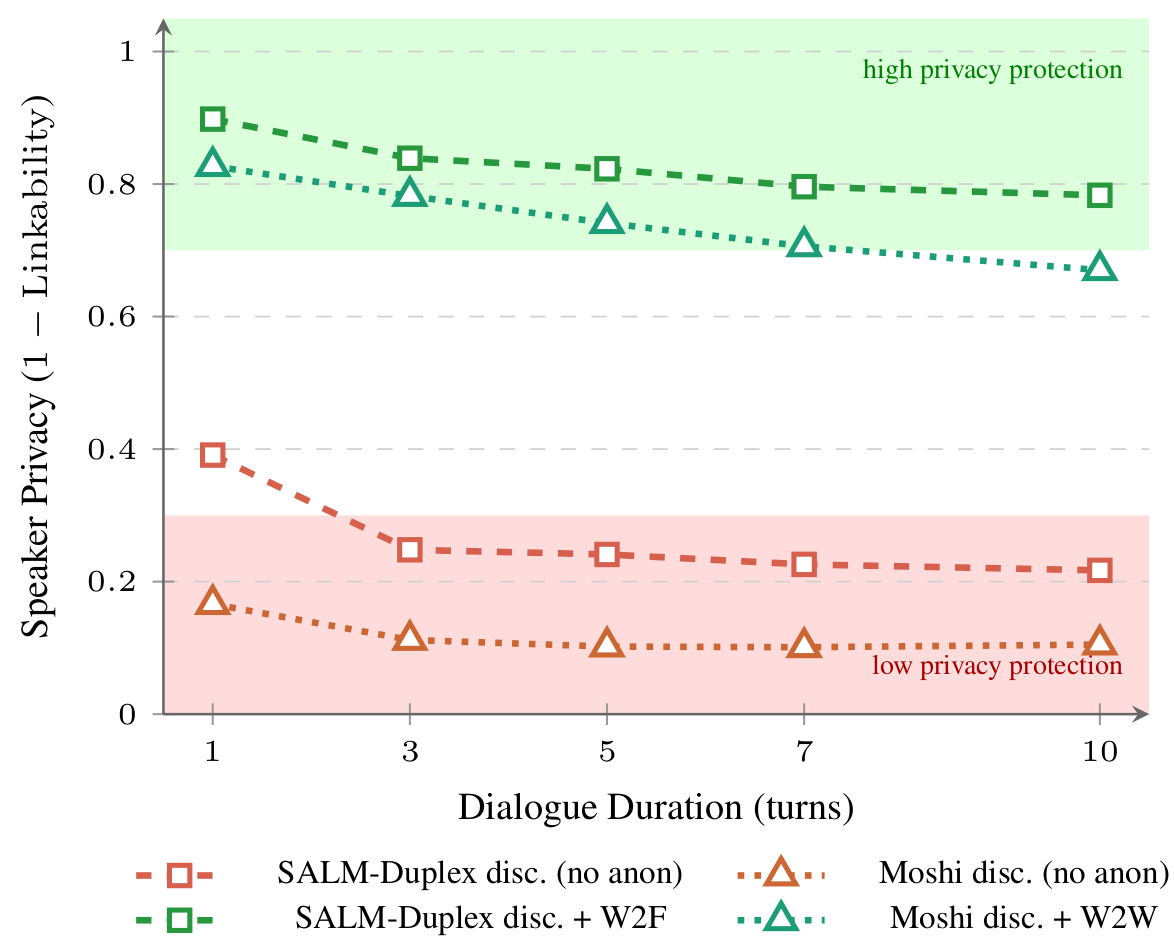
Figure 1: Speaker privacy (1 − Linkability) vs. dialogue turn count for discrete encoders (SALM-Duplex and Moshi); higher = better privacy. Red lines: no anonymization; green lines: post-anonymization. Without anonymization, both systems drop into the red zone within a few turns; anonymization lifts privacy into the green zone, though Moshi + W2W shows gradual degradation over dialogue length.
Privacy, Quality & Efficiency
| Model | User Encoder |
Anon. | Privacy | Quality | Efficiency | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EER↑ | Lnk↓ | sBLEU↑ S2T |
sBLEU↑ S2S |
sBERT↑ S2T |
sBERT↑ S2S |
RTFx↑ | FRL↓ | TTSR↑ | Int.L.↓ | ISR↑ | |||
| Moshi | discrete | – | 6.4 | 0.90 | 7.18 | 6.85 | 0.50 | 0.48 | 17 | 0.50 | 0.85 | 1.24 | 0.45 |
| discrete | W2W | 36.9 | 0.35 | 5.20 | 5.00 | 0.39 | 0.38 | – | 0.72 | 0.72 | 1.31 | 0.38 | |
| SALM- Duplex |
discrete | – | 11.2 | 0.79 | 4.18 | 3.15 | 0.45 | 0.29 | 238 | 0.44 | 0.85 | 1.03 | 0.96 |
| discrete | W2F | 41.0 | 0.23 | 3.57 | 1.49 | 0.39 | 0.20 | – | 0.50 | 0.68 | 1.18 | 0.93 | |
| continuous | – | 28.5 | 0.29 | 6.91 | 6.35 | 0.59 | 0.50 | 263 | 0.68 | 0.97 | 0.60 | 0.99 | |
| continuous | W2W | 34.6 | 0.24 | 6.46 | 5.49 | 0.55 | 0.45 | – | 0.80 | 0.94 | 0.57 | 0.98 | |
Table 1: Privacy, dialogue quality, and efficiency on the VPC2024 evaluation set. Higher EER and lower Linkability = stronger privacy; EER = 50% = perfect anonymization. Best privacy values in bold. Quality: higher sBLEU / sBERT = better. RTFx = 1/RTF; FRL = First Response Latency (s); TTSR = Turn-Taking Success Rate; Int.L. = Interruption Latency (s); ISR = Interruption Success Rate.
⚠ Key Findings
- Anon-W2F achieves the strongest privacy (41.0% EER, approaching 50% random chance), with the gain entirely from anonymization, not the encoder swap.
- Anon-W2W provides the largest relative gains on the most exposed systems: +30.5 pp for Moshi vs. +6.1 pp for SALM-Duplex continuous.
- Anonymization introduces moderate quality degradation (sBERT S2T drops 7–22% relative), but privacy gains consistently outweigh the cost, with EER improving 21–477% relative across setups.
Layer-wise EER (%)
| System | Encoder | Anon. | Early | Mid | Late | All |
|---|---|---|---|---|---|---|
| Moshi | discrete | – | 7.3 | 5.6 | 6.4 | 6.4 |
| discrete | W2W | 42.5 | 37.6 | 35.2 | 36.9 | |
| SALM- Duplex |
discrete | – | 7.5 | 14.0 | 20.1 | 11.2 |
| discrete | W2F | 43.8 | 40.5 | 40.1 | 41.0 | |
| continuous | – | 24.6 | 28.6 | 32.1 | 28.5 | |
| continuous | W2W | 31.5 | 33.7 | 35.3 | 34.6 |
Table 2: Higher = better privacy; 50% = chance level. All = mean-pooled over all layers. Moshi exhibits uniformly low EER across all layers (5.6–7.3%), while both SALM-Duplex variants show decreasing leakage from early to late layers, consistent with deeper layers progressively abstracting away speaker features.